Using PBS in Cassandra 1.2.0
14 Jan 2013
With the help of the Cassandra community, we recently released PBS consistency predictions as a feature in the official Cassandra 1.2.0 stable release. In case you aren’t familiar, PBS (Probabilistically Bounded Staleness) predictions help answer questions like: how eventual is eventual consistency? how consistent is eventual consistency? These predictions help you profile your existing Cassandra cluster and determine which configuration of N,R, and W are the best fit for your application, expressed quantitatively in terms of latency, consistency, and durability (see output below).
There are several resources for understanding the theory behind PBS, including talks, a demo, slides, and an academic paper. We’ve used PBS to look at the effect of SSDs and disks, wide-area networks, and compare different web services’ data store deployments. My goal in this post is to show how to profile an existing cluster and briefly explain what’s going on behind the scenes. If you prefer, you can download a (mostly) fully automated demo script instead.
Step One: Get a Cassandra cluster.
The PBS predictor provides custom consistency and latency predictions based on observed latencies in deployed clusters. To gather data for predictions, we need a cluster to profile. If you have a cluster running 1.2.0, you can skip these instructions.
The easiest way to spin up a cluster for testing is to use
ccm. Let’s start a 5-node
Cassandra cluster running on localhost:
git clone https://github.com/pcmanus/ccm.git
cd ccm && sudo ./setup.py install
ccm create pbstest -v 1.2.0
ccm populate -n 5
ccm start
export CASS_HOST=127.0.0.1If ccm start fails, you might need to initialize more loopback
interfaces (e.g., sudo ifconfig lo0 alias 127.0.0.2)—see the script.
Step Two: Enable PBS metrics on a Cassandra server.
The PBS predictor works by profiling message latencies that it sees in a production cluster. You only need to enable logging on a single node, and all reads and writes that the node performs will be used in predictions.
The prediction module logs latencies in a circular buffer with a FIFO
eviction policy (default: 20,000 reads and writes). By default, this
logging is turned off, saving about 300k of memory. To turn it on, use
a JMX tool to call the org.apache.cassandra.service.PBSPredictor
MBean’s enableConsistencyPredictionLogging method. You can use
jconsole1 or use a command line JMX interface
like jmxterm:
wget http://downloads.sourceforge.net/cyclops-group/jmxterm-1.0-alpha-4-uber.jar
echo "run -b org.apache.cassandra.service:type=PBSPredictor enableConsistencyPredictionLogging" | java -jar jmxterm-1.0-alpha-4-uber.jar -l $CASS_HOST:7100Step Three: Run a Workload
The PBS predictor is entirely passive: it profiles the reads and writes that are already occuring in the cluster. This means that predictions don’t interfere with live requests but also means that we need to have a workload to get results.1
We can use the Cassandra stress test, below executing 10,000 read and write requests with a replication factor of three.
cd ~/.ccm/repository/1.2.0/
chmod +x tools/bin/cassandra-stress
tools/bin/cassandra-stress -d $CASS_HOST -l 3 -n 10000 -o insert
tools/bin/cassandra-stress -d $CASS_HOST -l 3 -n 10000 -o readStep Four: Run predictions.
We can now connect to the node performing the profiling and have it
perform some Monte Carlo analysis for us. The consistency prediction
is triggered via JMX, but this time using the nodetool
administration interface packaged with Cassandra:
bin/nodetool -h $CASS_HOST -p 7100 predictconsistency 3 100 1Here’s some sample output from a run on one of our clusters. You can vary the replication factor, the amount of time you’d like to consider after writes, and even multi-versioned staleness. Remember that, aside from taking up some CPU on the predicting node, this profiling doesn’t affect query performance:
Performing consistency prediction
100ms after a given write, with maximum version staleness of k=1
N=3, R=1, W=1
Probability of consistent reads: 0.678900
Average read latency: 5.377900ms (99.900th %ile 40ms)
Average write latency: 36.971298ms (99.900th %ile 294ms)
N=3, R=1, W=2
Probability of consistent reads: 0.791600
Average read latency: 5.372500ms (99.900th %ile 39ms)
Average write latency: 303.630890ms (99.900th %ile 357ms)
N=3, R=1, W=3
Probability of consistent reads: 1.000000
Average read latency: 5.426600ms (99.900th %ile 42ms)
Average write latency: 1382.650879ms (99.900th %ile 629ms)
N=3, R=2, W=1
Probability of consistent reads: 0.915800
Average read latency: 11.091000ms (99.900th %ile 348ms)
Average write latency: 42.663101ms (99.900th %ile 284ms)
N=3, R=2, W=2
Probability of consistent reads: 1.000000
Average read latency: 10.606800ms (99.900th %ile 263ms)
Average write latency: 310.117615ms (99.900th %ile 335ms)
N=3, R=3, W=1
Probability of consistent reads: 1.000000
Average read latency: 52.657501ms (99.900th %ile 565ms)
Average write latency: 39.949799ms (99.900th %ile 237ms)Conclusions and Caveats
Once configured, the PBS predictions are both easy and fast to run. The great thing about predictions is that they can be run entirely off of the fast path; our PBS code module performs simple message profiling (timestamp logging), then, when prompted, performs forward prediction of how the system might behave in different scenarios in the background. This is a fundamental algorithmic property of the prediction problem, and, provided all nodes in the system attach the required timestamps on messages, only one node has to actually log data and perform predictions
Before I end, there are a few caveats to the current implementation. (Warning: this is a bit technical.) First, we only simulate non-local operations. In Cassandra, a node can act as a coordinator and as a replica for a given operation. We only collect data for operations for which the predicting node was a coordinator, not a replica. This means that, for example, if the predicting node serves all reads locally, we won’t have enough data for accurate predictions. The reason we did this is because we’d otherwise have to model coordinator and data accesses, which gets tricky in a running cluster. Second, we don’t consider failures or hinted handoff. We do capture slow node behavior. Third, we don’t differentiate between column families or different data items. This (like the rest) was an engineering decision that I’m sure we could change in future releases.
Despite these limitations, I think the current functionality is useful for getting a sense of how clusters are behaving and the potential impact of replication parameters. Moreover, I’m confident that we can fix the above issues if there’s enough interest. If you’re interested in using, further developing, or learning more about this functionality, please let me know and we can talk. We built this implementation because we care about real-world research impact; let us know what you think.
Thanks to Shivaram Venkataraman, who co-authored our patch, and the Cassandra community, particularly Jonathan Ellis, for being so accommodating.
[1] You can run predictions without workloads, just not within Cassandra. Take a look at our paper or some old Python code.
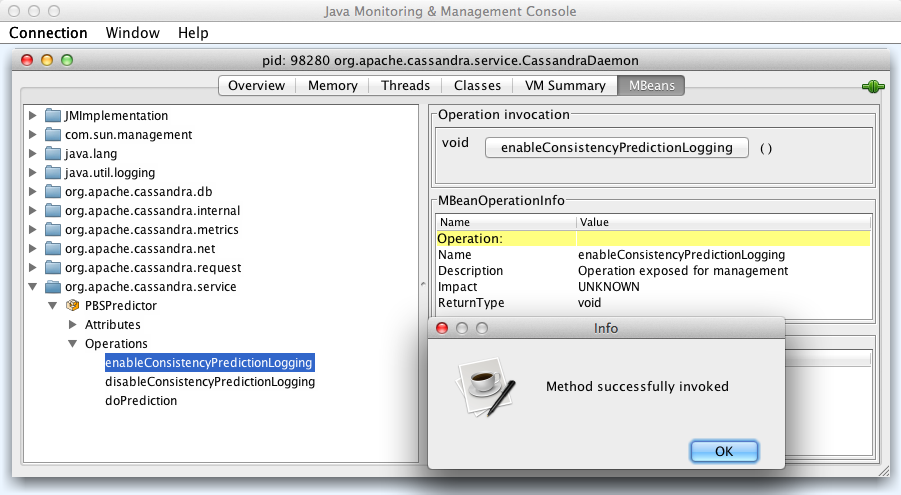
[2] This is ugly, so I put the instructions down
here. Run jconsole (if you used CCM, your 127.0.0.1 node will likely
have the lowest PID), click MBeans, then
org.apache.cassandra.service (bottom of the menu), PBSPredictor,
Operations, enableConsistencyPredictionLogging, then click the
enableConsistencyPredictionLogging button (screenshot
here).
{kind=link}
Read More
- How To Make Fossils Productive Again (30 Apr 2016)
- You Can Do Research Too (24 Apr 2016)
- Lean Research (20 Feb 2016)
- I Loved Graduate School (01 Jan 2016)
- NSF Graduate Research Fellowship: N=1 Materials for Systems Research (03 Sep 2015)
- Worst-Case Distributed Systems Design (03 Feb 2015)
- When Does Consistency Require Coordination? (12 Nov 2014)
- Data Integrity and Problems of Scope (20 Oct 2014)
- Linearizability versus Serializability (24 Sep 2014)
- MSR Silicon Valley Systems Projects I Have Loved (19 Sep 2014)